
Diario da Universidade de Vigo
Foi realizada polo enxeñeiro informático luso Carlos Adriano de Oliveira Gonçalves
Unha tese propón técnicas de aprendizaxe multirelacional para mellorar a clasificación de documentos científicos
Co obxectivo de avanzar na área da intelixencia artificial da minaría de textos
Na tese avánzase no uso de repositorios de literatura médica
Gráfica da arquitectura deseñada

Carlos Adriano de Oliveira Gonçalves é o autor da tese
A minaría de textos é unha área da intelixencia artificial que ten cobrado importancia nos últimos anos debido á gran cantidade de datos textuais que se deben manexar durante os procesos de toma de decisións e no desenvolvemento de estratexias en diversos sectores da sociedade. Na súa tese de doutoramento, o enxeñeiro informático luso Carlos Adriano de Oliveira Gonçalves afonda con éxito no uso da aprendizaxe multirelacional para mellorar a clasificación de documentos científicos de texto completo.
A tese levou por título Multi-relational learning for full text scientific document classification, estivo dirixida polos doutores Eva Lorenzo Iglesias (Universidade de Vigo) e Rui Camacho (Universidade do Porto) e foi realizada no marco do programa de doutoramento Sistemas de Software Intelixentes e Adaptables e do grupo SING (Next Generation Computer Systems Group), da Escola Superior de Enxeñaría Informática do campus de Ourense. Segundo explica o seu autor, “a clasificación de documentos é unha das técnicas máis importantes en moitas contornas”. No campo da medicina, detalla, o número de documentos que manexan os repositorios de literatura médica como o National Center for Biotechnology Information (NCBI) ou Medline ten medrado exponencialmente nos últimos anos. “Isto ten provocado a necesidade de desenvolver técnicas e métodos computacionais máis eficientes para buscar e clasificar documentos para extraer coñecemento relevante que impulse novos achados na investigación científica”, afirma Carlos Gonçalves.
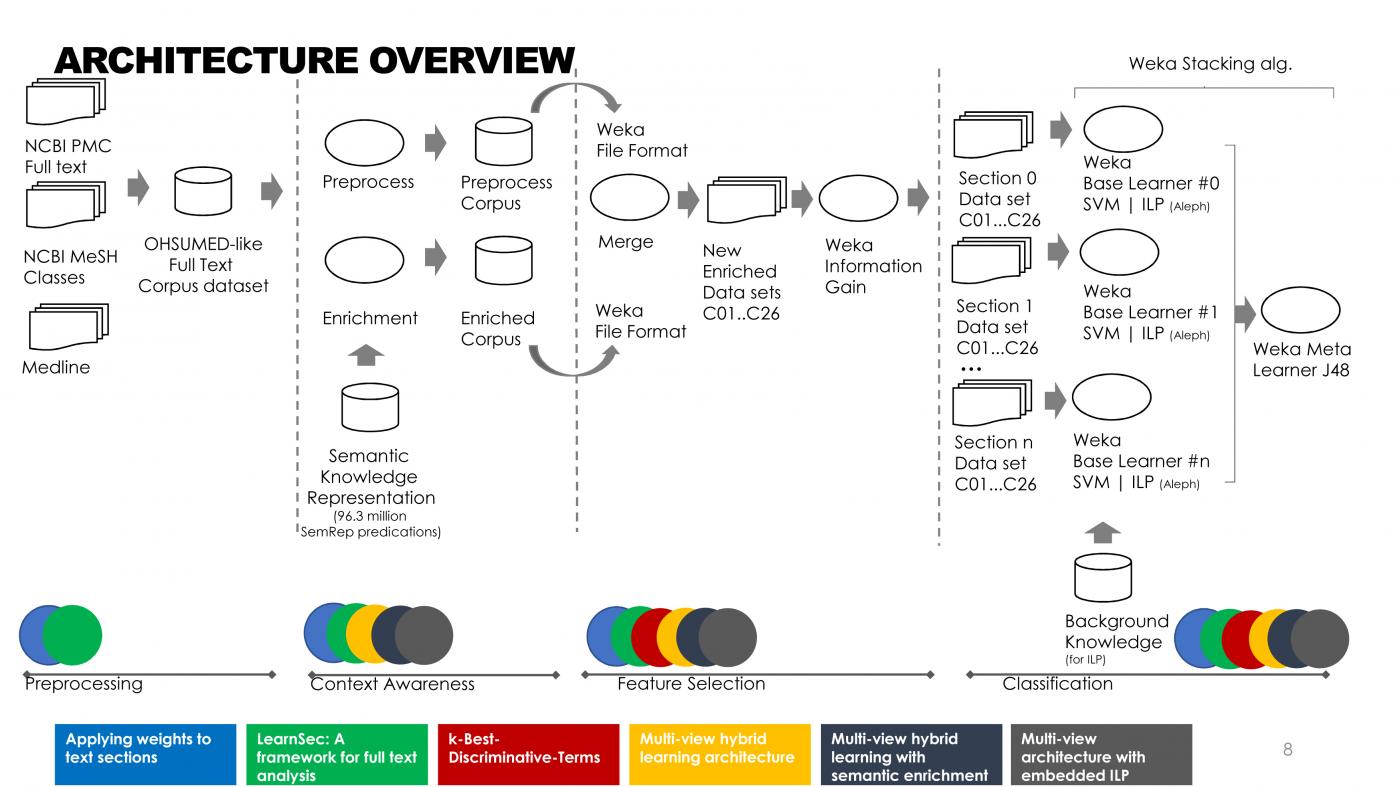
Os enfoques escollidos para extraer información das bases de datos de literatura científica, sinala o xa doutor pola UVigo, “soen depender exclusivamente dos títulos e resumos (abstracts) dos artigos científicos para a clasificación dos documentos”. Porén, na súa tese quixo avaliar a utilidade de empregar non só títulos e resumos senón textos completos para acadar unha mellor clasificación de documentos científicos. Para iso creou un corpus de documentos a texto completo a partir do corpus orixinal de OHSUMED coa incorporación doutros compoñentes, como os termos MeSH (encabezamentos de temas médicos) de MEDLINE e os documentos a texto completo dispoñibles no repositorio de PubMed Central, realizando a partir deste corpus diferentes experimentos. Os documentos foron divididos en diferentes secciones para estudar o impacto individual de cada sección no proceso de clasificación (así como o impacto da combinación de diferentes tramos) e para poder aplicar un algoritmo de aprendizaxe diferente a cada sección e estudar o impacto dos algoritmos multirelacionais.
Resultados positivos
Os resultados obtidos amosan que se se procesa o texto completo acádanse bos valores (tendo como referencia os valores Kappa) en máis corpus que se só se emprega título e resumo (tres corpus fronte a dez). Na tese sinálase igualmente que “tamén se demostra claramente que agregar seccións de documentos no proceso de clasificación mellora substancialmente os resultados na gran maioría dos conxuntos de datos fronte ao procesamento só de título e resumo”. O estudo realizado, indica o seu autor, “levou á conclusión de que é crucial utilizar todas as seccións dos documentos en lugar de só os títulos e resumos”.
Froito da investigación realizada, Carlos Gonçalves desenvolveu “un novo enfoque para a clasificación de documentos a texto completo utilizando unha representación multivista do documento a partir das seccións que o compoñen”. Así, detalla, “proponse un novo enfoque para o proceso de clasificación de documentos a texto completo utilizando unha representación baseada nunha arquitectura de múltiples vistas (seccións)”. Segundo explica o enxeñeiro informático, a comparación experimental cos métodos de clasificación cunha soa vista do documento indica “que a arquitectura proposta é mellor cando se utiliza para a clasificación de documentos a texto completo”. Ademais, engade, “analizáronse os resultados obtidos polos clasificadores para ver que vistas proporcionan os mellores resultados, mostrando que a sección Resultados ten os mellores resultados Kappa para todos os corpus examinados, mentres que a sección Conclusións ten os peores resultados en case todas as probas”.
Sobre a investigación realizada, o seu responsable explica que “a hipótese fundamental que guiou esta tese foi avaliar se o uso de programación lóxica inductiva (ILP), sistema de aprendizaxe multirelacional, podería mellorar os resultados cando se aplica ao proceso de clasificación. Deste xeito, no marco da tese realizouse a primeira implementación que integra un algoritmo multirelacional nunha ferramenta de minaría de datos como é WEKA, desenvolvendo un novo método discriminativo denominado k-BDT (k-Best-Discriminative-Terms). “Embeber un algoritmo de ILP na coñecida ferramenta de minaría de datos WEKA permite a representación multivista proposta, así como a axilidade para usar diferentes tipos de algoritmos de maneira máis eficiente”, apunta o enxeñeiro informático. “Os resultados obtidos foron moi prometedores, mostrando que utilizando documentos a texto completo, os algoritmos proposicionais e multirelacionais lograron mellores resultados en termos de medidas F-measure e Kappa que os resultados alcanzados ata o momento”, afirma. Este enfoque, engade, contribuíu na tese a acelerar o proceso de construción de solucións de aprendizaxe conxunto (ensembled learning) que utilizan diferentes tipos de algoritmos.
Por último, no marco do estudo tamén se realizou un enriquecemento semántico do corpus OHSUMED empregando o Repositorio Semántico (SemRep), concluíndo que a aplicación destas técnicas a documentos de texto completo mellora significativamente a tarefa de clasificación de textos.